
Nagiosから警告メール
ある日突然サービスを提供しているサーバーを監視する監視サーバーから警告メールが届いた。
警告メールは日常茶飯事、特に驚くことではないが、その時はいつもと違っていた。
警告内容
警告のあった監視対象サーバーは、OpenVZ内の一つのコンテナ(VPS)。ウェブ閲覧やリモートログイン、その他負荷状態やメモリー使用量等何も問題なく見えが監視サーバーが警告を発する。
警告の内容を見ると、
・ディスク容量
・メモリー
・ロードアベレージ
・ログインユーザー数
・データベース稼働数
等で、外部から直接監視できないもの。つまり監視対象サーバー上で稼働しているエージェント監視のみで警告が発せられていることが分かった。
監視対象サーバー上でエージェントが実行するプログラムとパラメーターを与えると各監視項目はきちんと値が取れる。
ということは、監視サーバーと監視対象サーバー間の情報のやり取りが上手くいかなくなっていることが推測される。
OpenVZ上のログ
OpenVZホストでdmesgをタイプすると、「TCP: too many of orphaned sockets」が下のようにずらりと表示(※CTIDの箇所は、実際にはコンテナIDが入ります)。
[6786511.969474] TCP: too many of orphaned sockets (1 in CTID)
[6786512.970135] TCP: too many of orphaned sockets (1 in CTID)
[6786513.074045] TCP: too many of orphaned sockets (1 in CTID)
[6786513.970224] TCP: too many of orphaned sockets (1 in CTID)
[6786514.948179] TCP: too many of orphaned sockets (1 in CTID)
[6786514.970906] TCP: too many of orphaned sockets (1 in CTID)
[6786515.971590] TCP: too many of orphaned sockets (1 in CTID)
表示された内容から、該当するコンテナのTCPソケット周りを調べれば良さそう。
/proc/user_beancounters
OpenVZはここを見れば状態が分かります。コンテナ内に入り、
# cat /proc/user_beancounters とタイプするとこのように表示。
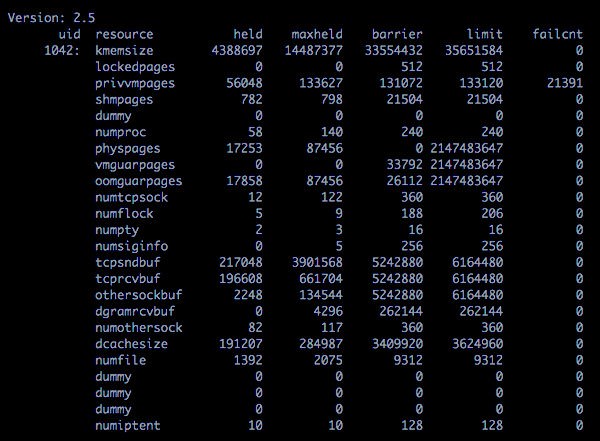
対応策
failcntを見るとメモリ容量が足りないことは明らかでこちらに目が行ってしまう。でも、「TCP: too many of orphaned sockets」に関してはやはりnumtcpsockが重要。
resource held maxheld barrier limit failcnt
numtcpsock 12 122 360 360 0
maxheldは122で、barrierやlimitの360の30%程度なので余裕がありそうに見えるが、OpenVZホスト上のdmesgには上記のログが記録され続けているので、numtcpsockの値を上げることに。
# vzctl set 1042 –numtcpsock 600:600 –save
これでdmesgのログが止まり、監視サーバーからの警告も停止する。
参考リンク:Re: Out of socket memory [message #14999 is a reply to message #14956]








この記事へのコメントはありません。